軟件學(xué)院組織師生代表團(tuán)專程赴西安,開展了一系列深入的訪企拓崗活動(dòng),旨在深化校企合作,共同探索網(wǎng)絡(luò)技術(shù)軟件研發(fā)的新路徑,取得了顯著進(jìn)展。
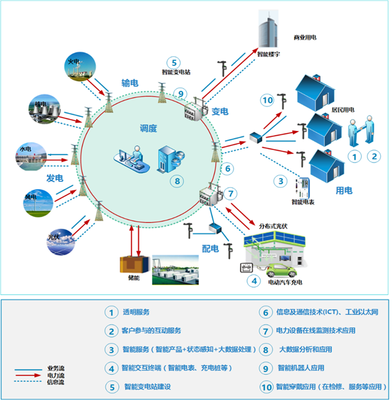
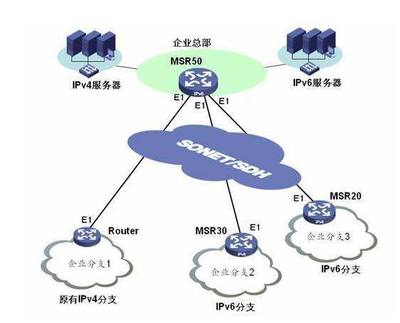
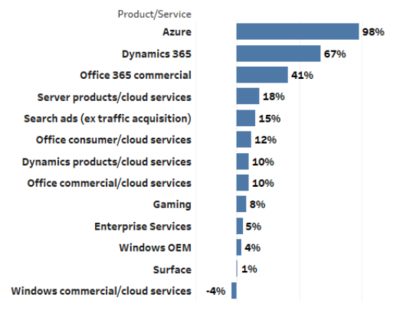
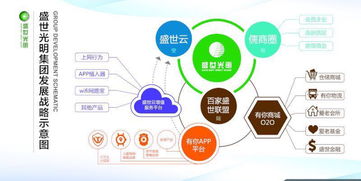
西安作為國家重要的高新技術(shù)產(chǎn)業(yè)基地和軟件產(chǎn)業(yè)集聚區(qū),擁有眾多在云計(jì)算、大數(shù)據(jù)、網(wǎng)絡(luò)安全及物聯(lián)網(wǎng)等領(lǐng)域領(lǐng)先的科技企業(yè)。此次訪問中,學(xué)院代表團(tuán)先后走訪了多家知名企業(yè),包括專注于網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)的創(chuàng)新公司、致力于網(wǎng)絡(luò)安全解決方案的領(lǐng)軍企業(yè),以及推動(dòng)軟件定義網(wǎng)絡(luò)(SDN)和網(wǎng)絡(luò)功能虛擬化(NFV)技術(shù)應(yīng)用的先鋒團(tuán)隊(duì)。通過實(shí)地參觀、技術(shù)交流和座談研討,學(xué)院師生深入了解了當(dāng)前網(wǎng)絡(luò)技術(shù)軟件研發(fā)的前沿動(dòng)態(tài)、市場需求以及行業(yè)對人才的核心要求。
在訪企過程中,雙方就聯(lián)合培養(yǎng)高素質(zhì)軟件人才、共建實(shí)習(xí)實(shí)訓(xùn)基地、開展產(chǎn)學(xué)研合作項(xiàng)目等議題進(jìn)行了廣泛而務(wù)實(shí)的探討。企業(yè)代表高度認(rèn)可軟件學(xué)院在理論教學(xué)與實(shí)踐結(jié)合方面的成果,并表達(dá)了強(qiáng)烈的合作意愿。多家企業(yè)當(dāng)場提出具體崗位需求,涵蓋了網(wǎng)絡(luò)協(xié)議開發(fā)工程師、云計(jì)算平臺軟件工程師、網(wǎng)絡(luò)安全分析師、系統(tǒng)架構(gòu)師等多個(gè)方向,為學(xué)院畢業(yè)生拓展了優(yōu)質(zhì)的就業(yè)渠道。企業(yè)也歡迎學(xué)院推薦優(yōu)秀學(xué)生參與實(shí)習(xí),提前融入實(shí)際項(xiàng)目研發(fā),實(shí)現(xiàn)從校園到職場的平滑過渡。
尤為值得關(guān)注的是,圍繞“網(wǎng)絡(luò)技術(shù)軟件的研發(fā)”這一核心主題,校企雙方達(dá)成了多項(xiàng)合作意向。計(jì)劃共同設(shè)立聯(lián)合實(shí)驗(yàn)室或研發(fā)中心,聚焦于下一代互聯(lián)網(wǎng)、智能網(wǎng)絡(luò)運(yùn)維、邊緣計(jì)算等關(guān)鍵技術(shù)領(lǐng)域,開展協(xié)同攻關(guān)。企業(yè)將提供真實(shí)的項(xiàng)目場景和技術(shù)支持,學(xué)院則發(fā)揮其在算法研究、軟件工程方法論和人才培養(yǎng)方面的優(yōu)勢,推動(dòng)技術(shù)創(chuàng)新與成果轉(zhuǎn)化。這種深度合作不僅有助于加速網(wǎng)絡(luò)技術(shù)軟件的研發(fā)進(jìn)程,應(yīng)對日益復(fù)雜的網(wǎng)絡(luò)環(huán)境挑戰(zhàn),也為學(xué)生提供了寶貴的實(shí)踐平臺,增強(qiáng)了他們的工程能力和創(chuàng)新意識。
此次西安之行,是軟件學(xué)院主動(dòng)對接產(chǎn)業(yè)需求、服務(wù)區(qū)域經(jīng)濟(jì)發(fā)展的重要舉措。通過“走出去”訪企拓崗,學(xué)院不僅拓寬了學(xué)生的就業(yè)視野,更搭建起校企之間穩(wěn)固的橋梁,為網(wǎng)絡(luò)技術(shù)軟件研發(fā)注入了新的活力。軟件學(xué)院將繼續(xù)深化此類合作,定期組織交流活動(dòng),推動(dòng)課程內(nèi)容與行業(yè)標(biāo)準(zhǔn)接軌,培養(yǎng)更多適應(yīng)時(shí)代發(fā)展的高層次軟件專業(yè)人才,共同書寫校企合作共贏的新篇章。